

Recently, I heard a phrase that calculus is the universal language of change, and I found it so accurate. Here is my feeble attempt at proving that the formula for making nominal changes to parameters for arriving at the best fit for a model using gradient descent is the same, whether it is logistic regression or linear regression; the only difference is the nature of change, linear in the case of linear regression and non-linear (sigmoid) in the case of logistic regression.
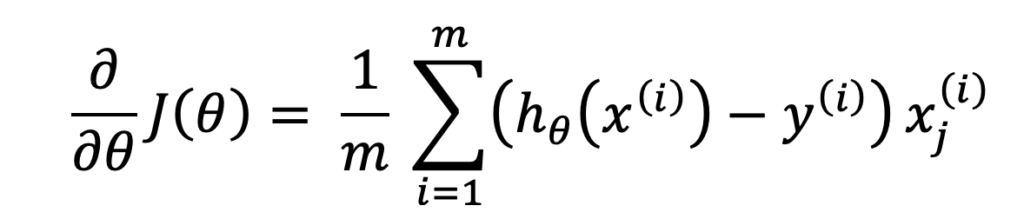
I tell my kids that math can only be learned by putting the pen on the paper, and here, I proved it again by doing the math on the whiteboard. I have a much better understanding of how backpropagation works in Neural Networks and how they arrive at the best-fitting parameters for a model.